This lab is about softmax function, its usage in both softmax regression and in neural networks when solving multiclass classification
This Softmax Function is part of DeepLearning.AI course: Machine Learning Specialization / Course 2: Advanced Learning Algorithms: Multiclass classification You will build and train a neural network with TensorFlow to perform multi-class classification in the second course of the Machine Learning Specialization. Ensure that your machine learning models are generalizable by applying best practices for machine learning development. You will build and train a neural network using TensorFlow to perform multi-class classification in the second course of the Machine Learning Specialization. Implement best practices for machine learning development to ensure that your models are generalizable to real-world data and tasks. Create and use decision trees and tree ensemble methods, including random forests and boosted trees.
This is my learning experience of data science through DeepLearning.AI. These repository contributions are part of my learning journey through my graduate program masters of applied data sciences (MADS) at University Of Michigan, DeepLearning.AI, Coursera & DataCamp. You can find my similar articles & more stories at my medium & LinkedIn profile. I am available at kaggle & github blogs & github repos. Thank you for your motivation, support & valuable feedback.
These include projects, coursework & notebook which I learned through my data science journey. They are created for reproducible & future reference purpose only. All source code, slides or screenshot are intellectual property of respective content authors. If you find these contents beneficial, kindly consider learning subscription from DeepLearning.AI Subscription, Coursera, DataCamp
Optional Lab - Softmax Function
In this lab, we will explore the softmax function. This function is used in both Softmax Regression and in Neural Networks when solving Multiclass Classification problems.
# Specify the GPU device to usegpus = tf.config.list_physical_devices('GPU')if gpus:# Set the GPU memory growth to Truetry: tf.config.experimental.set_memory_growth(gpus[0], True)exceptRuntimeErroras e:print(e)
Note: Normally, in this course, the notebooks use the convention of starting counts with 0 and ending with N-1, \(\sum_{i=0}^{N-1}\), while lectures start with 1 and end with N, \(\sum_{i=1}^{N}\). This is because code will typically start iteration with 0 while in lecture, counting 1 to N leads to cleaner, more succinct equations. This notebook has more equations than is typical for a lab and thus will break with the convention and will count 1 to N.
Softmax Function
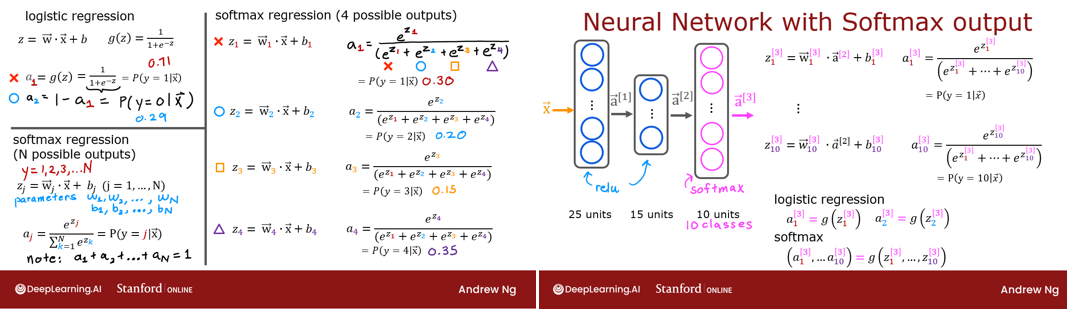
In both softmax regression and neural networks with Softmax outputs, N outputs are generated and one output is selected as the predicted category. In both cases a vector \(\mathbf{z}\) is generated by a linear function which is applied to a softmax function. The softmax function converts \(\mathbf{z}\) into a probability distribution as described below. After applying softmax, each output will be between 0 and 1 and the outputs will add to 1, so that they can be interpreted as probabilities. The larger inputs will correspond to larger output probabilities.
The softmax function can be written: \[a_j = \frac{e^{z_j}}{ \sum_{k=1}^{N}{e^{z_k} }} \tag{1}\] The output \(\mathbf{a}\) is a vector of length N, so for softmax regression, you could also write: \[\begin{align}
\mathbf{a}(x) =
\begin{bmatrix}
P(y = 1 | \mathbf{x}; \mathbf{w},b) \\
\vdots \\
P(y = N | \mathbf{x}; \mathbf{w},b)
\end{bmatrix}
=
\frac{1}{ \sum_{k=1}^{N}{e^{z_k} }}
\begin{bmatrix}
e^{z_1} \\
\vdots \\
e^{z_{N}} \\
\end{bmatrix} \tag{2}
\end{align}\]
Which shows the output is a vector of probabilities. The first entry is the probability the input is the first category given the input \(\mathbf{x}\) and parameters \(\mathbf{w}\) and \(\mathbf{b}\). Let’s create a NumPy implementation:
Code
def my_softmax(z): ez = np.exp(z) #element-wise exponenial sm = ez/np.sum(ez)return(sm)
Below, vary the values of the z inputs using the sliders.
Code
plt.close("all")plt_softmax(my_softmax)
As you are varying the values of the z’s above, there are a few things to note: * the exponential in the numerator of the softmax magnifies small differences in the values * the output values sum to one * the softmax spans all of the outputs. A change in z0 for example will change the values of a0-a3. Compare this to other activations such as ReLU or Sigmoid which have a single input and single output.
Cost
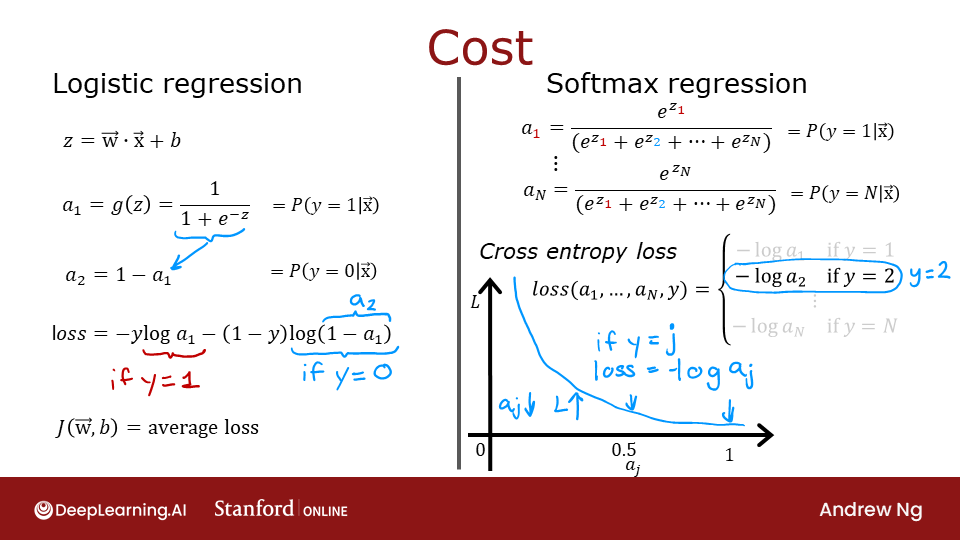
The loss function associated with Softmax, the cross-entropy loss, is: \[\begin{equation}
L(\mathbf{a},y)=\begin{cases}
-log(a_1), & \text{if $y=1$}.\\
&\vdots\\
-log(a_N), & \text{if $y=N$}
\end{cases} \tag{3}
\end{equation}\]
Where y is the target category for this example and \(\mathbf{a}\) is the output of a softmax function. In particular, the values in \(\mathbf{a}\) are probabilities that sum to one. >Recall: In this course, Loss is for one example while Cost covers all examples.
Note in (3) above, only the line that corresponds to the target contributes to the loss, other lines are zero. To write the cost equation we need an ‘indicator function’ that will be 1 when the index matches the target and zero otherwise. \[\mathbf{1}\{y == n\} = =\begin{cases}
1, & \text{if $y==n$}.\\
0, & \text{otherwise}.
\end{cases}\] Now the cost is: \[\begin{align}
J(\mathbf{w},b) = -\frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{N} 1\left\{y^{(i)} == j\right\} \log \frac{e^{z^{(i)}_j}}{\sum_{k=1}^N e^{z^{(i)}_k} }\right] \tag{4}
\end{align}\]
Where \(m\) is the number of examples, \(N\) is the number of outputs. This is the average of all the losses.
Tensorflow
This lab will discuss two ways of implementing the softmax, cross-entropy loss in Tensorflow, the ‘obvious’ method and the ‘preferred’ method. The former is the most straightforward while the latter is more numerically stable.
Let’s start by creating a dataset to train a multiclass classification model.
Code
# make dataset for examplecenters = [[-5, 2], [-2, -2], [1, 2], [5, -2]]X_train, y_train = make_blobs(n_samples=2000, centers=centers, cluster_std=1.0,random_state=30)
The Obvious organization
The model below is implemented with the softmax as an activation in the final Dense layer. The loss function is separately specified in the compile directive.
The loss function is SparseCategoricalCrossentropy. This loss is described in (3) above. In this model, the softmax takes place in the last layer. The loss function takes in the softmax output which is a vector of probabilities.
WARNING:absl:At this time, the v2.11+ optimizer `tf.keras.optimizers.Adam` runs slowly on M1/M2 Macs, please use the legacy Keras optimizer instead, located at `tf.keras.optimizers.legacy.Adam`.
WARNING:absl:There is a known slowdown when using v2.11+ Keras optimizers on M1/M2 Macs. Falling back to the legacy Keras optimizer, i.e., `tf.keras.optimizers.legacy.Adam`.
2023-04-30 18:48:17.679790: W tensorflow/tsl/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
63/63 [==============================] - 0s 2ms/step
[[5.44e-03 4.45e-03 9.54e-01 3.62e-02]
[9.98e-01 1.55e-03 7.32e-05 5.33e-06]]
largest value 0.9999995 smallest value 1.1039895e-11
Preferred
Recall from lecture, more stable and accurate results can be obtained if the softmax and loss are combined during training. This is enabled by the ‘preferred’ organization shown here.
In the preferred organization the final layer has a linear activation. For historical reasons, the outputs in this form are referred to as logits. The loss function has an additional argument: from_logits = True. This informs the loss function that the softmax operation should be included in the loss calculation. This allows for an optimized implementation.
WARNING:absl:At this time, the v2.11+ optimizer `tf.keras.optimizers.Adam` runs slowly on M1/M2 Macs, please use the legacy Keras optimizer instead, located at `tf.keras.optimizers.legacy.Adam`.
WARNING:absl:There is a known slowdown when using v2.11+ Keras optimizers on M1/M2 Macs. Falling back to the legacy Keras optimizer, i.e., `tf.keras.optimizers.legacy.Adam`.
Notice that in the preferred model, the outputs are not probabilities, but can range from large negative numbers to large positive numbers. The output must be sent through a softmax when performing a prediction that expects a probability. Let’s look at the preferred model outputs:
63/63 [==============================] - 0s 2ms/step
two example output vectors:
[[-1.18 -2.47 3.75 0.22]
[ 5.18 -0.19 -5.2 -7.79]]
largest value 12.0866 smallest value -14.279548
The output predictions are not probabilities! If the desired output are probabilities, the output should be be processed by a softmax.
two example output vectors:
[[6.96e-03 1.92e-03 9.63e-01 2.83e-02]
[9.95e-01 4.66e-03 3.10e-05 2.33e-06]]
largest value 0.9999994 smallest value 1.287414e-11
To select the most likely category, the softmax is not required. One can find the index of the largest output using np.argmax().
Code
for i inrange(5):print( f"{p_preferred[i]}, category: {np.argmax(p_preferred[i])}")
SparseCategorialCrossentropy or CategoricalCrossEntropy
Tensorflow has two potential formats for target values and the selection of the loss defines which is expected. - SparseCategorialCrossentropy: expects the target to be an integer corresponding to the index. For example, if there are 10 potential target values, y would be between 0 and 9. - CategoricalCrossEntropy: Expects the target value of an example to be one-hot encoded where the value at the target index is 1 while the other N-1 entries are zero. An example with 10 potential target values, where the target is 2 would be [0,0,1,0,0,0,0,0,0,0].